Scope
This vignette is the theoretical companion to Introduction to the
mhn Package. The Introduction shows what the four exported
functions (dmhn / pmhn / qmhn /
rmhn) and their moment helpers do; this note develops the
mathematical and algorithmic theory the package implements. We summarise
the Modified Half-Normal (MHN) family, the Fox–Wright
function that appears in its normalising constant, and the two sampling
schemes the package draws on — Sun, Kong & Pal (2023) and Gao &
Wang (2025).
We deliberately keep the treatment compact. Full proofs and the finer
numerical considerations live in the original papers (see References).
Two implementation-relevant points — the typesetting errata in Sun et
al. (2023) that the package silently corrects, and the benchmark-driven
rationale for the rmhn(method = "auto") crossover at 25 —
are inserted in §4 and §7 where they are most relevant.
The MHN(, , ) family
The MHN distribution has support and density
with , , . The three parameters control three independent factors of the density kernel:
| Parameter | Factor it controls | Role |
|---|---|---|
| shape | ||
| Gaussian tail | ||
| exponential tilt |
Three familiar distributions sit inside the family as exact special cases (Sun et al. 2023, Lemma 6):
| Constraint | Reduction |
|---|---|
| , i.e. sqrt-Gamma | |
| Truncated normal | |
| Half-normal with |
There is also a degenerate boundary limit, not listed in the
table: as
with
,
the MHN density converges to
.
The package does not handle this limit specially because
is required by the MHN parameter space; for a Gamma draw with
,
use stats::rgamma directly.
For each of the three finite special cases in the table
above —
,
,
and both together — the package detects the constraint within
sqrt(.Machine$double.eps) tolerance and dispatches to the
corresponding closed-form primitive in stats, so all four
exported functions (dmhn / pmhn /
qmhn / rmhn) are exact in those three regimes,
bypassing the general series-and-rejection machinery.
x <- seq(0.001, 4, length.out = 400)
plot(x, dmhn(x, alpha = 2, beta = 1, gamma = 1), type = "l", lwd = 2,
ylim = c(0, 1.4), ylab = "f(x)",
main = "MHN density at beta = 1, gamma = 1")
lines(x, dmhn(x, alpha = 5, beta = 1, gamma = 1), lwd = 2, col = "steelblue")
lines(x, dmhn(x, alpha = 1, beta = 1, gamma = 1), lwd = 2, col = "tomato")
lines(x, dmhn(x, alpha = 0.5, beta = 1, gamma = 1), lwd = 2, col = "darkorange")
legend("topright", bty = "n", lwd = 2,
col = c("darkorange", "tomato", "black", "steelblue"),
legend = c("alpha = 0.5 (no interior mode)",
"alpha = 1 (truncated normal)",
"alpha = 2 (log-concave)",
"alpha = 5 (log-concave, shifted right)"))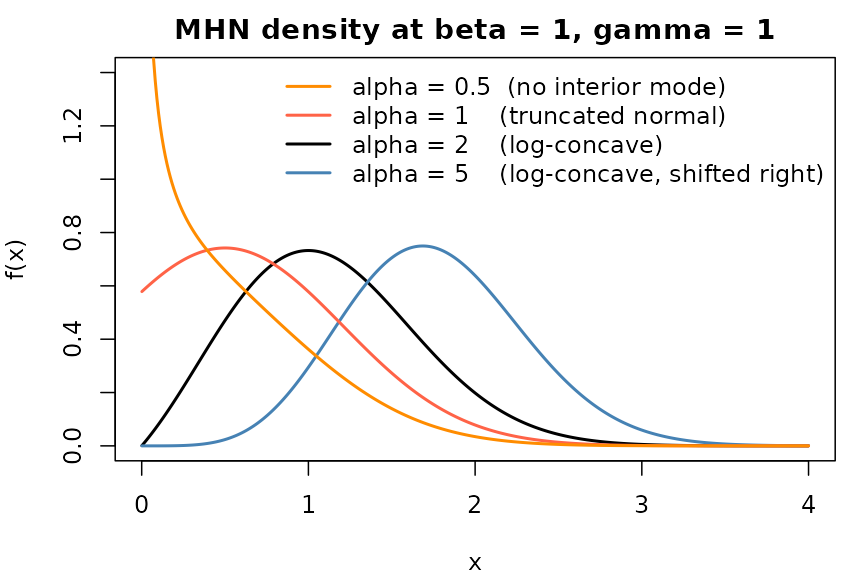
MHN density as alpha crosses the log-concavity threshold; beta = 1, gamma = 1 fixed.
The figure illustrates the qualitative claims developed in the next section. The density is log-concave whenever (Sun et al. 2023, Lemma 3a). For it has a finite interior mode in closed form (Sun et al. 2023, Lemma 3b); the borderline case reduces to the truncated normal, whose mode is — interior when , on the boundary otherwise. For the density is typically monotone decreasing with a boundary singularity at . The one exception is together with , where the density is not unimodal: it diverges at , dips to a local minimum, rises to a single interior local maximum, and then decays (Sun et al. 2023, Lemma 3c). At this threshold is , so the orange () curve in the figure sits in the strict monotone-decreasing regime, with no interior local maximum.
Shape and moments
Three facts from Sun et al. (2023) drive everything the package does with shape, moments, and the mode.
Log-concavity is a function of alone (Sun et al. 2023, Lemma 3a). For the density is log-concave irrespective of and ; for it is not. This single threshold is what splits the Gao & Wang (2025) RTDR sampler into its log-axis and original-axis branches in §6 below.
The mode has a closed form for (Sun et al. 2023, Lemma 3b):
For
the mode is
(the truncated-normal mode, Sun et al. 2023, Lemma 6b). For
the density is either monotone decreasing or develops a non-trivial
local maximum and local minimum, depending on the sign of
(Sun et al. 2023, Lemma 3c–d). The helper mhn_mode()
implements this case split and returns NA when no interior
mode exists.
Moments satisfy a two-term recurrence (Sun et al. 2023, Lemma 2b):
Together with the closed-form ratio for
in terms of
(Sun et al. 2023, Lemma 2a), this gives every higher moment. The helpers
mhn_mean(), mhn_var(),
mhn_skewness() and mhn_kurtosis() apply the
recurrence in C++ via Rcpp; the Introduction vignette shows
them in action. A useful sanity bound (Sun et al. 2023, Lemma 4c) is
for every
,
.
The Fox–Wright normalising constant
The normalising constant in the MHN density is
This series is absolutely convergent for every and every , and is strictly positive. It depends on only through the two-dimensional combination .
A useful organisational point: matters only for some of the package’s exported functions.
| Function group | Needs ? | Why |
|---|---|---|
dmhn, pmhn, qmhn
|
yes | sits in the density’s denominator and in the CDF series. |
mhn_mean, mhn_var,
mhn_skewness, mhn_kurtosis
|
yes | Moments are ratios . |
rmhn (Sun or RTDR path) |
no | enters both proposal scale and target as a common factor that cancels. |
The practical consequence is that any numerical issues in evaluating
— accumulated rounding in lgamma, or truncation error in
the series — can only affect d/p/q and the moment helpers;
they cannot leak into the sampler.
For evaluation, the package follows the case split of Sun et al. (2023, Lemma 9–11):
- gives .
- , and the corner, both reduce to closed forms involving (Sun et al. 2023, Lemma 9c).
- uses the alternating-free series of Sun et al. (2023, Lemma 10) with a pre-computed truncation point. All terms are positive, so there is no catastrophic cancellation.
-
switches to the integral representation (Sun et al. 2023, Lemma 11) and
uses Boost’s
gauss_kronrod(for ) ortanh_sinh(for , where the boundary singularity needs the double-exponential rule).
Errata in Sun et al. (2023)
The published paper has two typesetting errors that touch the implementation. Each is corrected in the supplementary derivation, and the package follows the corrected form.
Mixture weights in Lemma 7. The main-text statement of Lemma 7 gives the weights for the mixture representation as . These do not sum to one, contradicting the definition of and the Poisson–Gamma hierarchical representation in Sun et al. (2023, Lemma 5a). The correct form, reproduced in the supplementary proof of Lemma 7 (Supplementary §2.13), is i.e. drop the leading and use in the argument instead of . This affects Algorithm 2 only, which the package does not implement; the correction is recorded here for completeness.
Series truncation discriminants , in Lemma 10. The truncation point of the series is the smallest for which (with an analogous bound for ). Reducing this to a quadratic in gives a discriminant whose last term is (and for ). The main-text statement of Lemma 10 prints these as and — a single missing power of . The supplementary derivation (Supplementary §2.2.1, §2.2.2) carries throughout, in agreement with the rederivation. The corrected form is what the package uses in src/mhn_psi_series.cpp (marked with an
// ERRATAcomment); evaluating at the published form would give a too-small truncation point and silently lose precision.
Sampling: Sun et al. (2023)
Sun et al. (2023) propose three Accept–Reject schemes, indexed by the
sign of
and a coarse split on
.
Two of them — Algorithm 1 and Algorithm 3 — are implemented in the
package and reachable via rmhn(method = "sun"). Algorithm 2
is not, and this section explains the reason.
Algorithm 1 — ,
For each parameter triple, Algorithm 1 constructs two proposal distributions — a Normal with mean and variance , and a — each with a multiplicative envelope constant and . Setup chooses whichever envelope is tighter ( or the reverse). The two optima and have closed forms (Sun et al. 2023, Theorem 1b), so setup is cheap. The acceptance probability is bounded below by 0.8 for (Sun et al. 2023, Theorem 2e). For no uniform lower bound is proved, but the original Figure 2 shows empirically high acceptance throughout that range.
Algorithm 3 —
When the tilt is non-positive, Theorem 3 of Sun et al. (2023) supplies a proposal kernel based on an AM–GM-type inequality. With a tuning point and the exponent , the candidate is
The construction works for every ; the uniform acceptance bound (Sun et al. 2023, Theorem 4c) is proved only for , but the procedure also samples correctly when . The matching point is initialised from a closed-form heuristic of Sun et al. (2023, §4.2): for and a more elaborate expression based on the mode and the rightmost inflection point for . The package then applies a single Newton-Raphson refinement step in both regimes, producing , whose acceptance probability is within of the optimum across the parameter range tabulated in Sun et al. (2023, Table 1).
Why Algorithm 2 is not implemented
Algorithm 2 targets with via the mixture representation
The mixture-component sampler needs a truncation point chosen so that the tail mass beyond is below a target tolerance (Sun et al. 2023, Lemma 8). For large this truncation grows like , and the whole scheme degrades catastrophically — Gao & Wang (2025, Table 1) report a slowdown of up to against RTDR in the most extreme case . The package therefore declines to implement Algorithm 2 and routes to RTDR, where the acceptance bound (next section) holds uniformly.
Sampling: Gao & Wang (2025) RTDR
Gao & Wang (2025) introduce a Relaxed Transformed Density Rejection (RTDR) sampler that comes with a uniform lower bound on the acceptance probability across the entire parameter space. Three ideas drive the construction.
-concavity
Standard TDR builds piecewise-linear envelopes on top of a log-transformed density. RTDR generalises to the family
A density is -concave if is concave. Logarithmic concavity (the usual TDR setting) is the special case. The package’s RTDR implementation uses on the log-axis density for the branches because accommodates the slower decay of when the original has a boundary singularity at .
Working on the log axis when
When the density on blows up at the left endpoint and is not amenable to direct envelope construction. The change of variable yields
which is bounded and unimodal (Gao & Wang 2025, Lemma 3.3). RTDR operates on for and on directly for .
The four regions
After scale normalisation
(so we may assume
),
the RTDR envelope construction splits into four regions based on
.
The
in the table below is the normalised tilt
;
for a general
the package’s rmhn(method = "rtdr") rescales internally and
compares
against the boundary
.
| Region | Envelope target | Reference | ||
|---|---|---|---|---|
| (a) | any | log-concave | Gao & Wang (2025, Theorem 3.1) | |
| (b) | any | -concave | Gao & Wang (2025, Corollary 3.1; Theorem 3.2) | |
| (c) | -concave | Gao & Wang (2025, Lemma 3.5; Theorem 3.2) | ||
| (d) | with inflection at | Gao & Wang (2025, Theorem 4.4) |
Region (a) is the easiest: is log-concave, two tangent lines and a constant segment suffice. Regions (b) and (c) reuse the same envelope on , with only the validity argument differing. Region (d) is the hardest — has an inflection point and the envelope needs secant segments on the log-convex side, with growing logarithmically in .
Why “relaxed”
The classical TDR construction asks for optimal tangent contact points, which generally have no closed form and must be found by Newton iteration. Gao & Wang (2025, Theorem 2.1) show that the acceptance bound (equivalently, acceptance probability ) holds as long as the contact points lie anywhere inside a fixed interval — namely
Setup is therefore a handful of cheap iterations that terminate as soon as the bracket is hit, with no need for a precise Newton solution. This is the main practical edge of RTDR over Algorithms 1 / 3 of Sun et al. (2023) in Gibbs-style workloads where changes every iteration: the setup cost is amortised over a single draw instead of many, and a cheap setup wins.
Composing the bounds in Gao & Wang (2025, Theorems 3.1, 3.2, 4.4) yields the headline guarantee of RTDR: for every with , , , the acceptance probability is at least . The three algorithms of Sun et al. (2023) only have parameter-dependent guarantees (and only on parts of the parameter space — see §5).
A quick sanity check that the RTDR sampler converges to the right distribution in all four regions — empirical means from RTDR vs theoretical means across regions (a), (b), (c), (d), each based on 5000 draws:
cases <- data.frame(
region = c("(a)", "(b)", "(c)", "(d)"),
alpha = c(2.0, 0.7, 0.3, 0.3),
gamma = c(0.5, 1.0, 0.5, 5.0)
)
set.seed(42)
empirical <- mapply(
function(a, g) mean(rmhn(5000, alpha = a, beta = 1, gamma = g, method = "rtdr")),
cases$alpha, cases$gamma
)
theoretical <- mapply(mhn_mean, cases$alpha, beta = 1, cases$gamma)
data.frame(cases,
empirical_mean = round(empirical, 4),
theoretical_mean = round(theoretical, 4))
#> region alpha gamma empirical_mean theoretical_mean
#> 1 (a) 2.0 0.5 1.0126 1.0016
#> 2 (b) 0.7 1.0 0.6442 0.6424
#> 3 (c) 0.3 0.5 0.2972 0.2823
#> 4 (d) 0.3 5.0 2.3321 2.3221The four rows hit the right means to two-to-three decimal places — about the sampling tolerance at .
The rmhn(method = "auto") dispatch
rmhn exposes three values of method:
"sun" (force the Sun Algorithm 1 / 3 path),
"rtdr" (force the Gao & Wang RTDR path), and
"auto" (default). The "auto" route is the
package’s recommendation; it composes the four shortcuts above into one
decision tree (this is the Step 3.7.3 final form, confirmed by the
benchmarks under inst/benchmarks/):
rmhn(n, alpha, beta, gamma, method = "auto")
│
▼
┌─ alpha = 1, gamma = 0 → half-normal (Sun et al. 2023, Lemma 6c)
│
├─ gamma = 0 → sqrt-Gamma (Sun et al. 2023, Lemma 6a)
│
├─ alpha = 1 → truncated normal (Sun et al. 2023, Lemma 6b)
│
├─ alpha < 1 and gamma > 0
│ → RTDR (regions (b) / (c) / (d), Gao & Wang 2025, Theorems 3.2, 4.4)
│
├─ alpha > 1 and gamma > 0
│ → Sun Algorithm 1 (Sun et al. 2023, Theorems 1, 2)
│
└─ gamma < 0
├─ samples_per_setup ≥ 25 → RTDR (region (a))
└─ samples_per_setup < 25 → Sun Algorithm 3Write
for the samples_per_setup quantity in the last branch,
where , , are the recycled lengths of the three parameter vectors. The intuition follows from decomposing the expected time per draw as
where is the one-off cost of preparing the proposal (a single formula plus at most one Newton step for Sun Algorithm 3; an iterative contact-point search for RTDR), is the expected number of proposals per accepted draw, and is the cost of one proposal cycle (sample plus acceptance log-ratio evaluation).
For the two samplers sit on opposite ends of this trade-off:
-
Sun Algorithm 3 has a cheap setup —
has a closed form, and the optional Newton refinement uses one
boost::math::digammaevaluation — but a more expensive per-proposal: every proposal callsrgamma, evaluates the fractional power , and the acceptance log-ratio carries the same term. -
RTDR (region (a)) has a more expensive
setup: each contact point
,
is found by an iterative search that terminates as soon as
lands in the bracket
.
But the per-proposal is light: sampling from the piecewise
envelope is straight arithmetic plus a single
log, and the acceptance ratio adds only two morelogs.
When is large the per-proposal term dominates and RTDR wins; when it is small — the Gibbs case where each iteration redraws — the setup term dominates and Sun Algorithm 3 wins. The crossover at 25 is the round value chosen inside the empirical break-even window observed at every one of the 20 surveyed cells in inst/benchmarks/auto_dispatch.R.
A small concrete demonstration: with set.seed aligned,
method = "auto" and the expected forced method
produce bit-identical draws on each branch.
# Branch: alpha < 1 and gamma > 0 --> expects RTDR
set.seed(7); auto1 <- rmhn(20, alpha = 0.7, beta = 1, gamma = 2)
set.seed(7); rtdr1 <- rmhn(20, alpha = 0.7, beta = 1, gamma = 2, method = "rtdr")
identical(auto1, rtdr1)
#> [1] TRUE
# Branch: alpha > 1 and gamma > 0 --> expects Sun Algorithm 1
set.seed(7); auto2 <- rmhn(20, alpha = 3, beta = 1, gamma = 2)
set.seed(7); sun2 <- rmhn(20, alpha = 3, beta = 1, gamma = 2, method = "sun")
identical(auto2, sun2)
#> [1] TRUE
# Branch: gamma < 0 with samples_per_setup < 25 --> expects Sun Algorithm 3
set.seed(7); auto3 <- rmhn(5, alpha = 2, beta = 1, gamma = -1)
set.seed(7); sun3 <- rmhn(5, alpha = 2, beta = 1, gamma = -1, method = "sun")
identical(auto3, sun3)
#> [1] TRUEThe three TRUE outputs are the same invariant that
tests/testthat/test-rmhn.R enforces as a regression
test.
References
Sun, J., Kong, M., & Pal, S. (2023). The Modified-Half-Normal distribution: Properties and an efficient sampling scheme. Communications in Statistics – Theory and Methods, 52(5), 1507–1536.
Gao, F. & Wang, H.-B. (2025). Generating modified-half-normal random variates by a relaxed transformed density rejection method. Communications in Statistics – Simulation and Computation.
Robert, C. P. (1995). Simulation of truncated normal variables. Statistics and Computing, 5(2), 121–125.